
Surviving the Big One: Modernizing NASCAR's Disaster Recovery Capabilities with AWS
NASCAR collaborated with CapTech, an official NASCAR Technology Partner, to design, develop, and deploy a modernized disaster recovery (DR) cloud data platform.
Summary
NASCAR is pushing the boundaries of technology both on and off the track to continuously improve performance and reliability. As part of NASCAR’s modernization efforts, it identified an opportunity to improve race critical database resiliency, reliability, and availability.
NASCAR collaborated with CapTech, an official NASCAR Technology Partner, to design, develop, and deploy a modernized disaster recovery (DR) cloud data platform to reduce operational risk and improve overall performance of their technical infrastructure.
In eight weeks, CapTech and NASCAR successfully deployed new AWS services using DevOps pipelines, migrated prioritized on-premises databases, and re-routed supporting application traffic resulting in the first set of DR enabled databases actively operating in the cloud.

Challenge
NASCAR identified the need to address on-premises vulnerabilities to network outages by developing and executing a comprehensive strategy for migrating databases to the cloud, bolstered by DR resiliency with the aim to achieve three key outcomes:
- Minimize Downtime: Deploy infrastructure that is resilient to server failures and other potential issues significantly reducing downtime during outages.
- Improve Resiliency: Enable failover mechanisms to ensure that critical data and applications remain accessible in the event of hardware failures or natural disasters using both intra and cross region recovery methods.
- Retain Backup and Recovery Processes: Leverage native AWS backup and recovery processes to streamline data restoration in the event of a disaster to minimize recovery time and data loss.
Achieving these outcomes would support NASCAR’s primary objective: to continuously provide world class services, content, and experiences to its fanbase, partners, and supporters.
Approach
Cloud technology helped modernize and transform NASCAR’s disaster recovery capabilities, fortify its resilience against outages, and safeguard the continuity of its business operations.
To quickly deploy the right solution, NASCAR and CapTech developed a phased delivery plan detailing the order of operations, durations, and dependencies necessary to successfully complete the migration within a short, eight-week timeframe. The team then broke the plan into four discrete phases with frequent stakeholder checkpoints to collect feedback and maintain alignment.
Phase 1
Rapid Discovery and Design of Target State Solution
CapTech conducted a thorough review of the current state architecture with NASCAR experts and, together, they identified disaster recovery opportunities. These opportunities informed the target state architecture prioritizing scalability and resiliency to minimize downtime and data loss in the event of a disaster.
To achieve the desired resiliency and redundancy for NASCAR’s databases, the team designed a cloud-based architecture taking advantage of industry leading AWS tooling and functions:
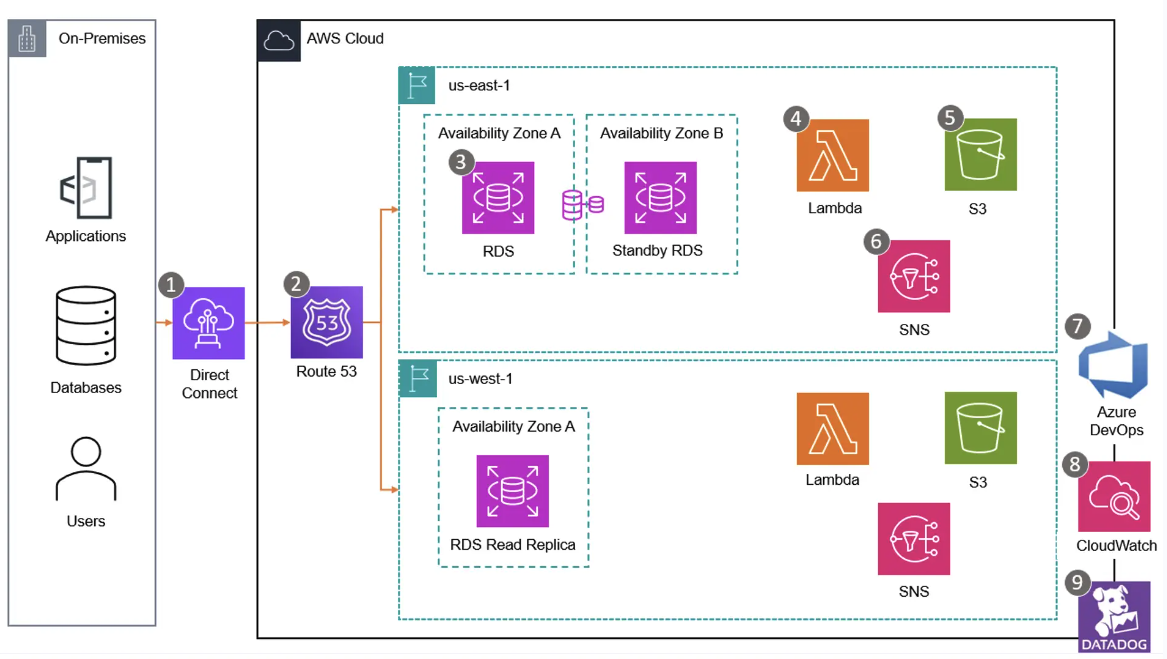
Amazon RDS with Multi-Availability Zone (AZ) functionality was selected; this automatically provisions and maintains a standby replica in a second availability zone in the same region with synchronous replication. When a failure is detected, Amazon RDS will automatically failover to the standby instance without manual intervention restoring connectivity typically within 60-120 seconds.
Phase 2
Migration Plan Development And Testing
With the design completed, a migration plan was developed to methodically move highest priority databases to the target cloud environment relying on native backup and restore processes.
To validate the design, a sandbox environment was provisioned with the target state infrastructure and architecture deployed. A representative subset of databases were migrated to the sandbox environment to support rigorous and thorough testing. Through testing the team was able to:
- Refine and optimize the cloud design.
- Validate the migration plan and approach.
- Automate the deployment process with Terraform Infrastructure as Code (IaC) and Azure DevOps pipelines.
- Determine any migration issues that would derail a production deployment.
- Deploy and validate Datadog monitors, alert thresholds, and notifications.
- Build confidence in production migration success.
Phase 3
Production Migration
Prior to going live, attention was turned to cross training and launch planning to ensure the team understood the migration process and their assigned roles and responsibilities.
- A series of knowledge transfer sessions were conducted to cross train and upskill the team on the new components and process.
- A communication plan was developed to keep stakeholders informed of the progress.
- A “war room” was stood up to ensure clear lines of communication were available to quickly resolve any issues uncovered during the migration and monitor overall progress.
With all migration pieces in place, a night was selected during the off-season to complete the production migration. Through partnership, collaborative teamwork, and dedication from all involved, all activities were completed successfully with minimal disruption to business operations.
Phase 4
Post Migration Monitoring And Training
After the production migration was completed, the team continued to monitor the new system for issues. When issues were identified, they were immediately triaged, prioritized, and resolved as necessary. Stakeholders were informed and updated of status and health of the new environment. As issues were closed out and the system reached a steady state, NASCAR and CapTech collectively determined the project to be a success.
Results
Operating on the modern, DR enabled cloud infrastructure, NASCAR is able to:
- Reduce the service restore time and data loss down from hours to minutes with minimal manual intervention
- Methodically migrate remaining on-prem databases using a vetted repeatable process to further improve their overall resiliency posture
- Maintain business continuity with minimal risk to service drops impacting daily operations
- De-risk critical race-day operations and data management procedures
- Improve overall reliability posture to consistently provide world class fan experiences 24/7/365

Related Insights


Client Stories
Centralizing Competition Data Through the Cloud

Videos