Blog November 25, 2019
Major League Sluggers & Machine Learning: Feature Selection Techniques to Maximize Your Model’s Predictive Power


The Case
Every November since 1980, managers and coaches throughout Major League Baseball have voted on the recipients of the Silver Slugger, an award that recognizes the most outstanding batter at all nine positions in both leagues. In recent years, player agents and team executives have collaborated to bake this offensive accolade into MLB contracts as a financial incentive. For instance, the Colorado Rockies are contractually obligated to dole out an additional $50,000 to Denver sports icon Nolan Arenado if he wins the silver hardware for National League Third Basemen.
Machine Learning, the new essential in Artificial Intelligence, paves a path for us to cultivate innovation and transform what’s possible within the realm of sports business. Feature selection, the process of selecting a subset of the most pertinent attributes in a model, has emerged as a robust source of value for analysts. Websites for baseball statistics and analysis, such as Fangraphs and Baseball-Reference, provide fans, front offices, and major media organizations with a multitude of filterable, performance-based datasets. By properly subjecting a custom dataset to Python’s feature selection techniques, we maximize our insights into the candidate landscape for the award.
The Problem
Suppose we are interested in designing a Machine Learning model that will predict the eighteen Silver Slugger recipients for 2019. Here are two feature selection techniques to effectively reduce noise, remove misleading data, and expedite our model’s training time:
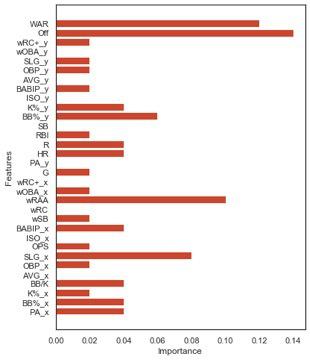
1. plot_feature_importances(): The “Feature Importance” Technique
Feature selection empowers our model with an accurate assessment of voters’ bias. The “Feature Importance” technique essentially rates the relevancy of every data feature in the historical context of award recipients. As the bar chart below shows, there are eight hitting statistics that we should absolutely drop from our model—every instance where “importance” equals 0. To further reduce the noise generated by redundancies in the dataset, we might also consider filtering out features that fail to meet a minimum importance score, such as 0.02 or 0.04. This data-cleaning process reveals that the managers and coaches of 2019 likely overlooked the inherent offensive skill captured in the “Weighted Runs Above Average” (wRAA) statistic, a critical feature of historically high importance, as demonstrated by their election of Ronald Acuña (30.3 wRAA) in place of both Ketel Marte (46.1) and Juan Soto (42.2) as a winner for National League Outfielders.
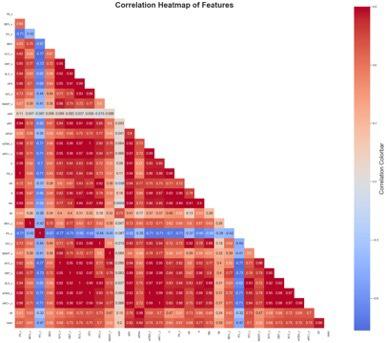
2. seaborn.heatmap(): The “Feature Engineering” Technique
Feature Engineering foolproofs our Machine Learning model of nonsensical variables that weaken its predictive power. For example, as the heatmap below illustrates, games played (G) and plate appearances (PA) share an understandably strong correlation of 0.99. Thus, we should drop one of these features from our model. Ultimately, we will want to account for all correlations that are at least +/- 0.90 as we manipulate the data into a new set of features. This specific model will produce at least two additional correct predictions when we implement the Feature Engineering technique to eliminate multicollinearity.
Results
Here are the true winners of the 2019 Silver Slugger Award, as elected by managers and coaches:
American League
Position | C | 1B | 2B | SS | 3B | OF | OF | OF | DH |
Player | Mitch Garver | Carlos Santana | DJ LeMahieu | Xander Bogaerts | Alex Bregman | Mike Trout | George Springer | Mookie Betts | Nelson Cruz |
National League
Position | C | 1B | 2B | SS | 3B | OF | OF | OF | P |
Player | J.T. Realmuto | Freddie Freeman | Ozzie Albies | Trevor Story | Anthony Rendon | Christian Yelich | Cody Bellinger | Ronald Acuña | Zack Greinke |
And here are the projections that our Machine Learning model generated, both with and without feature selection:
American League (NO FEATURE SELECTION)
Position | C | 1B | 2B | SS | 3B | OF | OF | OF | DH |
Player | Mitch Garver | Jose Abreu | DJ LeMahieu | Xander Bogaerts | Alex Bregman | Mike Trout | George Springer | Trey Mancini | Jorge Soler |
American League (FEATURE SELECTION)
Position | C | 1B | 2B | SS | 3B | OF | OF | OF | DH |
Player | Mitch Garver | Carlos Santana | DJ LeMahieu | Xander Bogaerts | Alex Bregman | Mike Trout | George Springer | Mookie Betts | Jorge Soler |
National League (NO FEATURE SELECTION)
Position | C | 1B | 2B | SS | 3B | OF | OF | OF | P |
Player | J.T. Realmuto | Pete Alonso | Ozzie Albies | Trevor Story | Nolan Arenado | Christian Yelich | Cody Bellinger | Ketel Marte | Steven Brault |
National League (FEATURE SELECTION)
Position | C | 1B | 2B | SS | 3B | OF | OF | OF | P |
Player | J.T. Realmuto | Pete Alonso | Ozzie Albies | Trevor Story | Nolan Arenado | Christian Yelich | Cody Bellinger | Ketel Marte | Steven Brault |
- ML Model – No Feature Selection: 11/18 correct picks = 61% accuracy
- ML Model – Feature Selection: 13/18 correct picks = 72% accuracy

